
Intro
HTTP is ubiquitous and is a crucial part of what we know as the "World Wide Web". Even though we all use it to do any interaction with the internet, the question is "what do we really know about HTTP"?
Hypertext Transfer Protocol (HTTP) was initially developed by Tim Barners-Lee in 1991 at CERN.
It was developed with the purpose of specifying communication between a client (e.g. our browser) and a server (e.g. computers running google.com) and serving the WWW as its top level, application layer protocol.
What is HTTP
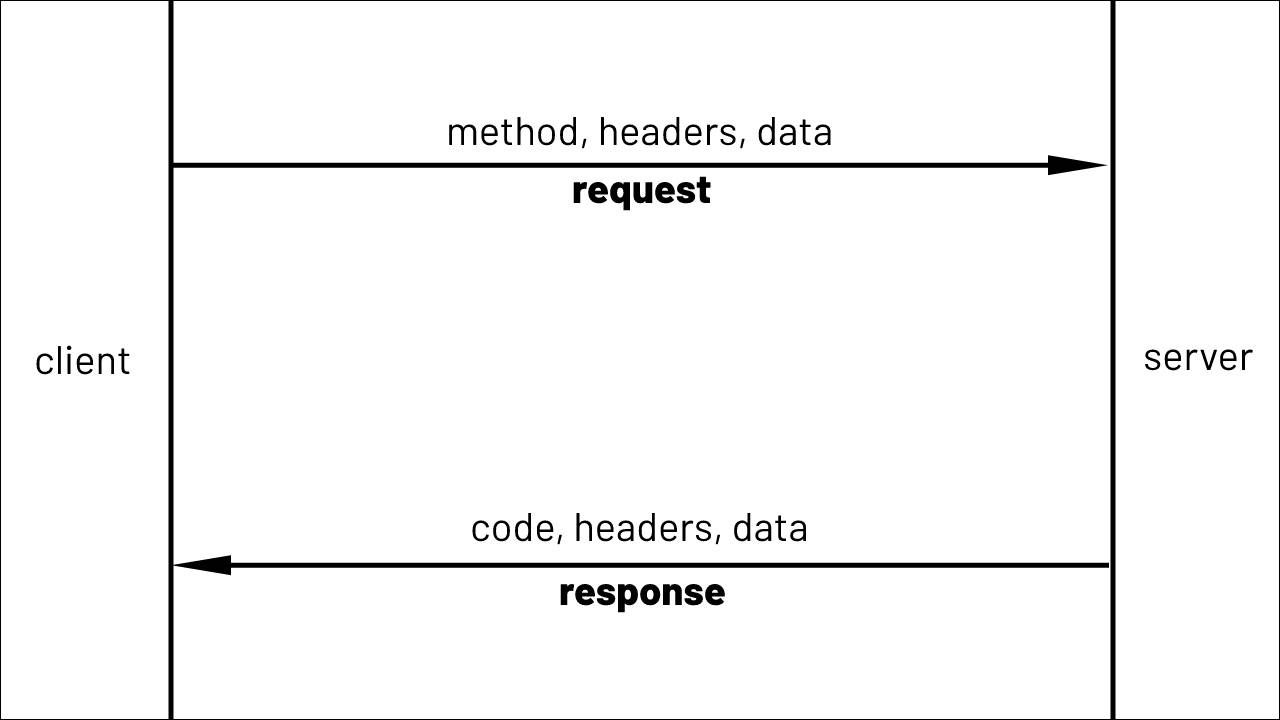
As mentioned, HTTP is an application layer protocol. It is designed for distributed information systems. It is a stateless protocol meaning there is no state stored in between requests.
The HTTP protocol specifies following:
- Methods
- Response Codes
- Headers
I like to use the metaphor of a restaurant. In a restaurant there is you (client), there is the kitchen (server) and there is the waiter (HTTP) managing the communication between the client and the kitchen.
HTTP Methods
There are 8 possible methods that a client can use on a resource over HTTP.
- OPTIONS
- GET
- HEAD
- POST
- PUT
- DELETE
- TRACE
- CONNECT
In the restaurant you can order (method) a salad (resource). You can complain (method) about the fish (resource) etc.
A typical website might have users. We can request a user (resource) be retrieved (GET method) or a user be created (POST method). We can request a user be deleted (DELETE method) or updated (PUT method).
# GET request for the resource google.com using CURL
# and saving it to the file google.html
curl -L https://google.com > google.html
Web applications that mostly do the above tasks are also called CRUD application where CRUD stands for create, read, update and delete.
Not all of the methods are always allowed for a resource. A might be able to create a user but not delete a user. In such a case where we want to find out what methods are allowed for a resource we use the OPTIONS method.
# OPTIONS request for the resource google.com using curl
# and supressing the response body (html)
curl -s -o /dev/null -v http://google.com -X OPTIONS
# Part of the response
< HTTP/1.1 405 Method Not Allowed
< Allow: GET, HEAD
Sometimes we want to only retrieve meta data (response headers) of a resource instead of the actual resource data itself. In that case we use the HEAD method.
# HEAD request for the resource google.com using curl
curl -L http://google.com -I
# part of the response
< HTTP/1.1 200 OK
Sometimes the communication between client and server exhibits misunderstanding without obvious reasons. The client starts investigating i.e. debugging and wants to know, what is happening with the request along the path to the resource. In that case we could use the TRACE method.
And finally, sometimes, for whatever reason, we don't have direct access to a resource yet we still would like to access it somehow. It would be nice if we had a middle man to proxy the communication between the client and the directly inaccessible server. If the a server allows it, we can use the CONNECT method and access a certain resource via proxy.
HTTP Codes
We might request a soup at the restaurant and after getting a negative answer from the kitchen, the waiter might say "Unfortunately, we don't have soup at the moment" or if we used HTTP response codes, "404 (Not found)". If everything went well with our request we would get a response code of 200 (OK).
From the example we can see that HTTP response codes represent meaningful answers from the server.
Response codes are categorized as follows:
- 1xx informational response – the request was received, continuing process
- 2xx successful – the request was successfully received, understood, and accepted
- 3xx redirection – further action needs to be taken in order to complete the request
- 4xx client error – the request contains bad syntax or cannot be fulfilled
- 5xx server error – the server failed to fulfill an apparently valid request
HTTP Headers
When ordering at the restaurant sometimes the name of a dish is not enough and we need to extend our order with additional information such as requesting an ingredient to be left out because we are allergic to it.
In communication over HTTP, clients and servers can, in requests and responses, pass additional meta information via HTTP headers.
# Example reponse headers from google.com using CURL
Content-Type: text/html; charset=ISO-8859-1
P3P: CP="This is not a P3P policy! See g.co/p3phelp for more info."
Date: Fri, 31 Dec 2021 20:17:28 GMT
Server: gws
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN
Transfer-Encoding: chunked
Expires: Fri, 31 Dec 2021 20:17:28 GMT
Cache-Control: private
Set-Cookie: NID=511=XqLjywAkjBKkgobLzGHMgpF4hmgmv2tkWsCYaMZdacVSDKesBZ5q8w_E35LMhAHEf-EanJ0zdGrj7xy7i2H6SZXR7KXoyLeYpkNcIXgggq7R0nbn58k0PyrQTzQn1_spcfpGArrGWOJQUTsr47wbgdtxo4GsP-oY2TQVG7djORE; expires=Sat, 02-Jul-2022 20:17:28 GMT; path=/; domain=.google.com; HttpOnly
HTTP headers can be grouped as follows:
- Request headers
- Response headers
- Representational headers
- Payload headers
Example request headers are:
- Accept: application/{mime}
example value: application/json
Tell the server which content types the client understands. Also available are Accept-Chartset, Accept-Encoding, Accept-Language and Accept-Datetime - Content-Type: application/{mime}
example value: application/json
Tell the server which type of content is the request body - Authorization: Basic {password}
example value: Basic ILUEDpoiewjfoAPEOIJ
If the resource we are trying to access requires basic authorization then we use this header to gain access. - User-Agent: {product} / {product-version} {comment}
example value: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)
Tell the server some information about the client agent.
Example response headers are:
- Set-Cookie: {cookie-name}={cookie-value}
example value: session=029456787620945679034576904
A server uses this header to send information to the client which the client will send back to the server later. - E-Tag: {value}
example value: 0294567-876209-4567903-4576904
This header is used in a caching mechanism where the server tags i.e. sends a response the E-Tag response header, a resource e.g. /user/john.
The client then uses the E-Tag value in subsequent requests for /user/john with the header If-No-Match and the E-Tag value.
This allows the server, if the content didn't change, to respond with a "304 Not Modified", save bandwidth and increase performance
There are many other HTTP headers and you can learn more about it developer.mozilla.org
Conclusion
HTTP is an essential part of the World Wide Web and as such we should be familiar with at least the basics of it. There is a lot more to HTTP than can fit in this post buthopefully it can serve as a small reminder or a basic introduction to the lovely HTTP protocol.
