
Intro
A crucial part of global scale and serverless applications is, of course, a serverless highly scalable and cost effective database. As Moore's law, unfortunately, became irrelevant, at least until something like quantum computing becomes useful, we had to start using a different approach and methodology with our databases. That approach, you guessed it, is NoSQL.
Unfortunately, the scaling benefits come at a cost of shift in approach, which we will explore in this post. The cost might not be as much as you think.
The Problem
How to transform our traditional entity relation models from many tables into one?

Normalization/Denormalization
When transitioning from SQL to NoSQL a big help will be understanding and brushing up on normalization and denormalization.
Normalization helps us keep our data consistent and not duplicated. Single table design requires us to denormalize and probably duplicate some of our data to fit in a single table.
How do multiple tables fit into only one table?
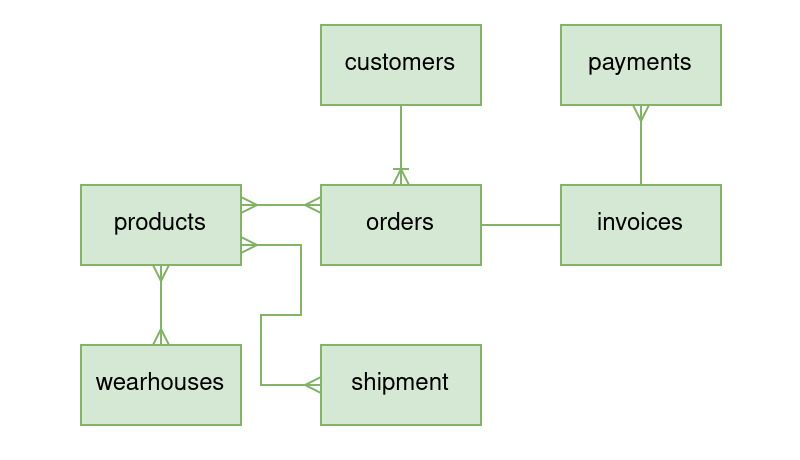
There are multiple things to consider when transitioning from normalized data to single table data but first we will take a look at how to do multiple entities in one table without relations.
Let's take these entities:

How would this look like in a single table?
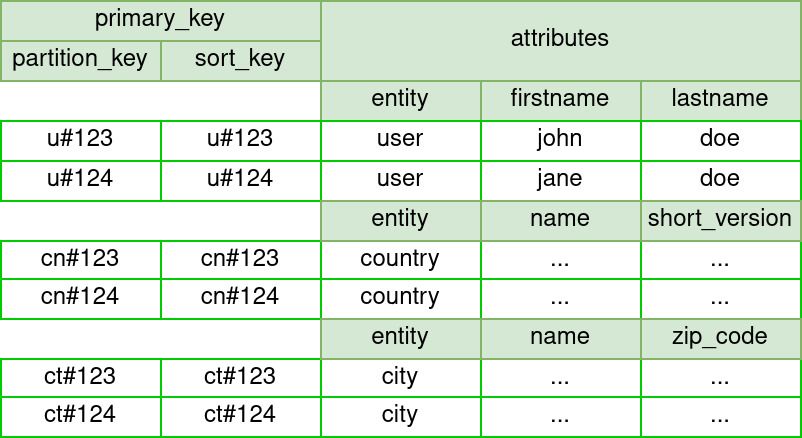
A simplified representation of the above would be:
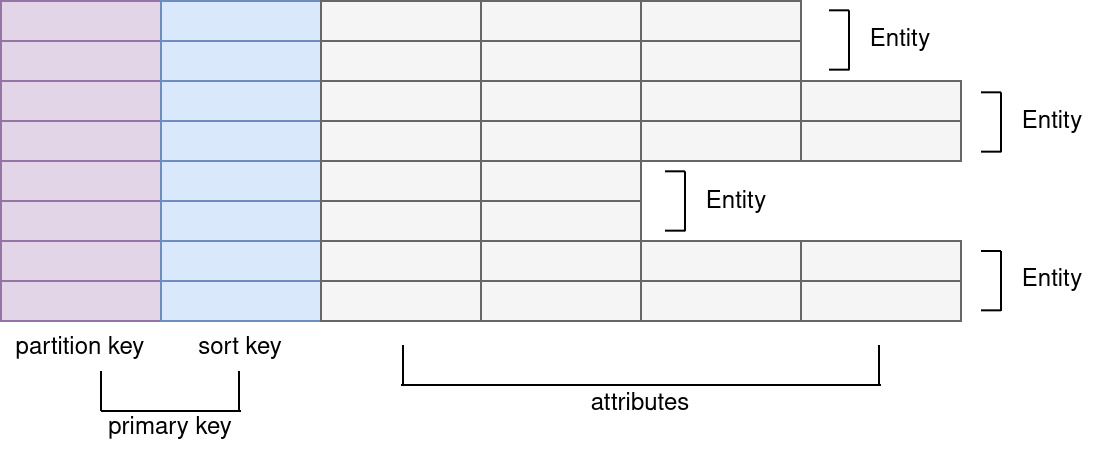
The first shift that we are making compared to our traditional normalized approach is that tables representing our entities become one table and entities become rows.
What is a partition key?
DynamoDB, and NoSQL databases in general, are designed with scale in mind. One of the main requirements for large scale is the ability to scale horizontally instead of a limited vertical scale approach. To achieve horizontal scalability with a database we need to physically partition the data and compute. Partition keys are used for horizontal scaling without sacraficing performance.
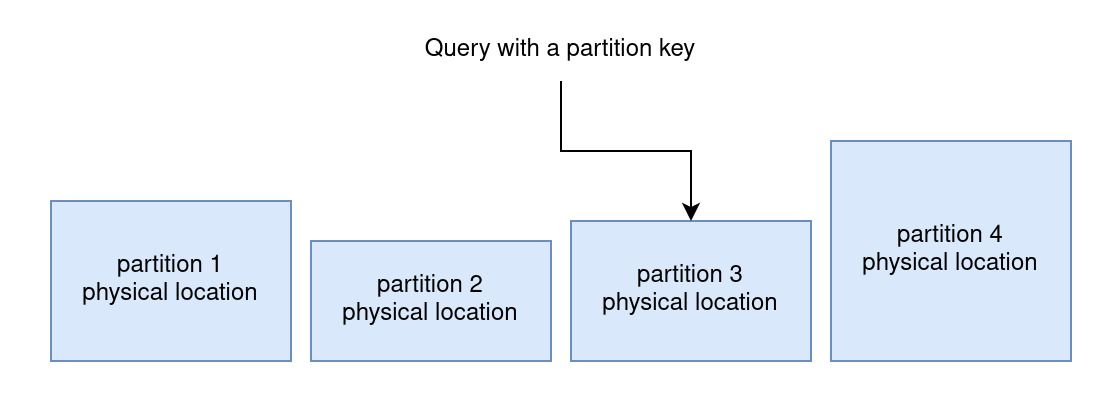
Based on the partition key, DynamoDB is able to find the location of the record you are looking for very quickly even at internet scale.
Caution
Having to many records on the same partition can cause throttling while querying that partition. Be careful to avoid this scenario.
What is a sort key?
A sort key, as the name suggests, determines the sorting of your records.
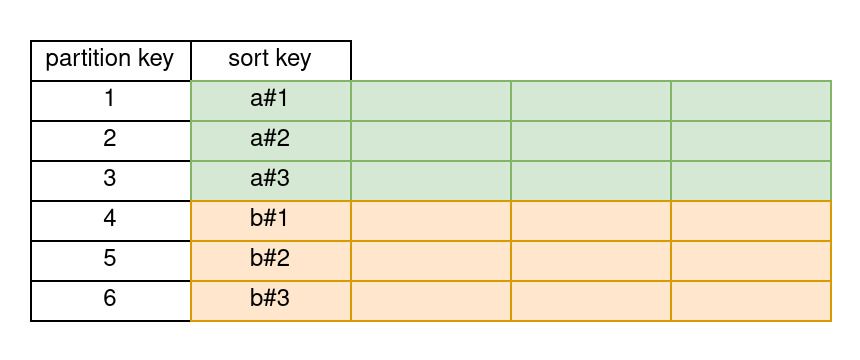
As you can see, all the "a#" records are grouped one after the other and all the "b#" records are grouped one after the other.
What is a primary key?
We could technically only use the partition key as the primary key for our records but that doesn't make sense with single table design. Instead our primary key will be a composite of the partition key and the sort key.
Why should I care about partition and sort keys?
Partition and sort keys are explained above but is that really all there is to it? As you guessed, it's not. The combination of the partition and sort key is actually what allows for entity relations in a single table.
How to design a one-to-many relationship?
Let's take e.g. a customer having many orders. In a normalized design we would have an orders table that references customers via a foreign key column containing customer ids. The customer_id column is telling us that an order belongs to a certain customer
In a single table design we will use the partition key to store the customer_id and the sort key to store the order_id.
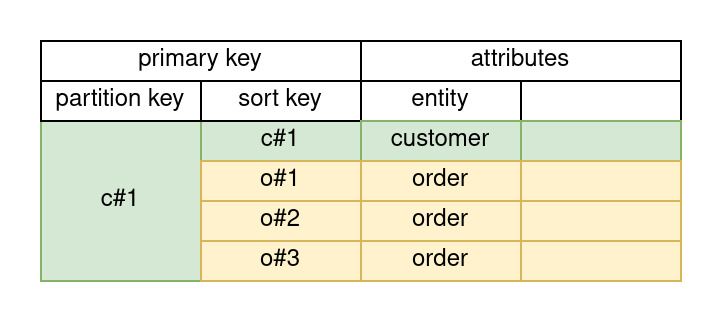
Since we are at it, let's also add products belonging to orders into the picture...
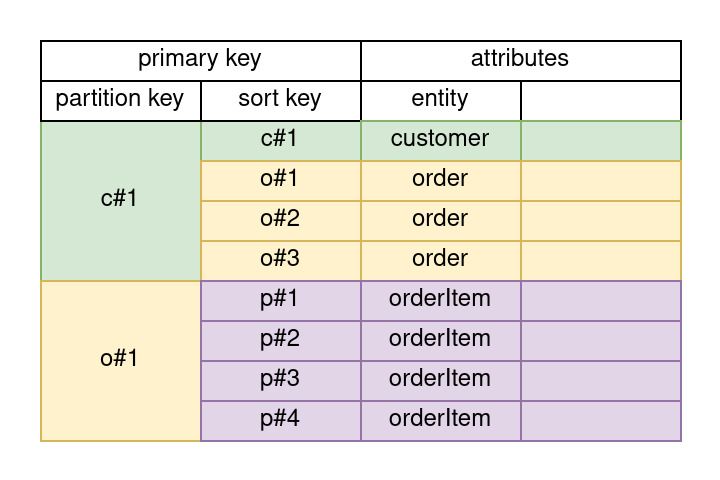
This design allows us to query all orders given a customer id and all products given an order id.
How to design a many-to-many relationship?
Let's take e.g. that we want to query all orders that contain a certain product. In a SQL world we might do this by joining the orders table onto the products table where order_id = product_id.
In the previous example where we have an order partition key containing products identified by the sort key, we cannot directly query the products without having an order id. To achieve this we need an additional index.
What are global secondary indexes?
In a single table DynamoDB we utilize additional indexes, so called "Global Secondary Indexes" (GSI's) instead of joins or intermediary tables to add additional pathways to our data.

This will result in an additional secondary partition (kept synchronized by dynamodb) that will look something like this ...
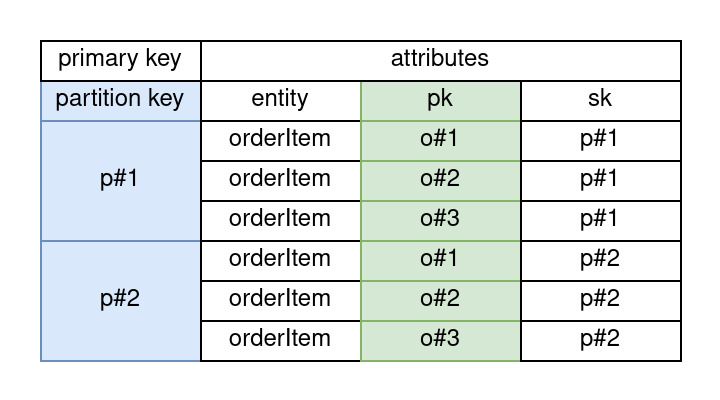
Having the product id as a partition key and the order id as an attribute we are now able to query all orders containing a certain product.
Can GSI's have sort keys?
Definitely! GSI's can also have sort keys that we can use for additional querying capabilities. In the above example we could have added a datetime sort key in addition to the product id partition key. This would have allowed us to easily and efficiently query all orders having a certain product within a certain time period.
What's the catch?
This does't sound that bad. What is the catch? The catch is that we don't have, on the fly, table joining capabilities. Instead we have to think about the queries (access patterns) we want to be making beforehand and design the single table accordingly utilizing partition keys, sort keys, GSI's, LSI's, background processes, change data capture, record decoration (sometimes duplication) etc. to accomodate necessary access patterns.
Summary
As I could hopefully get accross, "Single Table - Global Scale" database design might not be that difficult but it definitely requires a shift in approach and a bit more upfront planning. We might not need the switch today and can enjoy our good old SQL life but being aware of signle table design could help us immensely at a point in the future.



